
포도가게의 개발일지
쿠버네티스(k8s) 본문
하이퍼 바이저
- 가상 머신 모니터라고도 하는 하이퍼바이저는 가상 머신(VM)을 생성하고 실행하는 프로세스입니다.
vs
컨테이너 런타임
- 저수준 런타임
- namespace와 cgroup를 이용하여 컨테이너 자체를 만드는 일을 한다.
- 대표적인 저수준 런타임으로 runc가 있다
- 이미지로부터 컨테이너를 실행하는 기능은 없다.
- 고수준 런타임
- 저수준 런타임 위에 배치되어 이미지로부터 컨테이너를 실행할 수 있다.
- 대표적으로 containerd, cri-o등이 고수준 컨테이너 런타임이다.
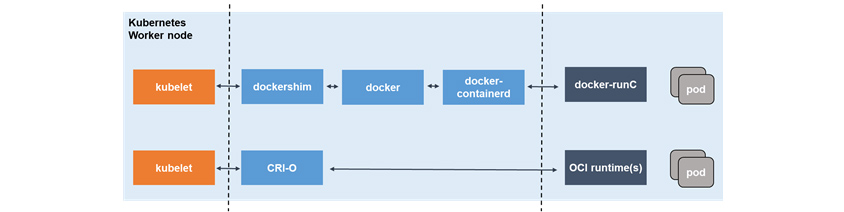
- docker
- docker의 경우 docker-containerd라는 고수준 런타임과 docker-runc라는 저수준 런타임을 이용하여 제공한다.
- docker가 기존에 가지고 있던 컨테이너 daemonm으로써의 기능을 containerd에게 넘겨 주었고, docker 데몬 자체는 containerd에 대한 클라이언트로서 기능한다.
- CRI
- 쿠버네티스에서 만든 컨테이너 런타임 인터페이스로 개발자들의 컨테이너 런타임 구축에 대한 진입장벽을 낮추어 준다.
- CRI-O
- CRI와 OCI에서 유래된 프로젝트로 컨테이너 런타임 및 이미지가 OCI와 호화되는 것에 중점을 두고 있습니다. cri 표준 컴포넌트를 최소한의 런타임으로 구현하며 쿠버네티스에서 모든 OCI 호환 런타임 및 컨테이너 이미지를 지원합니다.
- CRI-O는 컨테이너 실행을 목적으로 경량화 했기 때문에 도커가 제공하는 컨테이너 생성 및 이미지 빌드와 같은 기능은 제공하지 않습니다.
쿠버네티스에서는 데이터 플레인(서비스 사이의 네트워크 트래픽을 관리하는 서비스 매시 애플리케이션)이라고 불리는 서버를 여러 대 실행시켜 그 위에 가상 오케스트레이션 계층을 구축하고 거기에서 컨테이너가 동작한다.
컨트롤 플레인을 통해 데이터 플레인이 어떻게 동작할지 설정하는 애플리케이션을 뜻한다.
- 클러스터와 노드를 관리
ETCD
- 모든 클러스터 데이터에 대한 쿠버네시트 백업 저장소.
- 가용성 높은 키 값 저장소
노드
- 쿠버네티스 클러스터에서 작업자 시스템 역할을 하는 vm 또는 물리적 컴퓨터.
- 각 노드에는 노드를 관리하고 컨트롤플레인과 통신하기 위한 kubelet이라는 agent가 있음.
- 노드에는 containerd 또는 docker와 같은 컨테이너 작업을 처리하기 위한 도구가 필요
- 노드는 컨트롤 플레인이 노출하는 kubernetes api를 사용하여 컨트롤 플레인과 통신한다.
- 최종 사용자는 api를 직접 사용하여 클러스터오 상호 작용할수있다.
- 모든 노드는 레지스트리에서 image를 가져오고 애플리케이션을 실행하는 컨테이너 런타임(Docker같은)입니다.
kubectl
- kubernetes cli
- kubernetes api와 통신함
쿠버네티스 내부에서 실행 중인 pod는 격리된 private network에서 실행됩니다. 기본적으로 동일한 cluster 내의 다른 pod 및 서비스에서는 볼 수 있지만, 네트워크 외부에서는 볼 수 없습니다.
파드는 쿠버네티스 최소단위이면 하나이상의 컨테이너를 동작시킬 수 있다. 컨테이너 통합본??
레플리카셋은 파드를 얼마나 동작시킬지 관리하는 오브젝트이다. 파드의 수를 설정하면 그만큼의 파드가 동작하는것을 보장한다.
디플로이먼트는 새롭게 릴리즈하거나 부하증가에 따랄 레플리카셋 수를 변경하는 등 여러가지 동작이발생하는데 이들은 디플로이먼트로 관리 할 수 있다.
서비스는 배포한 파드를 쿠버네티스 클러스터 외부에 공개하기 위한 구조를 제공한다. 가장 대표적인 방법이 로드밸런서를 사용하는 것이다. 클러스터 내에 파드 여러 개를 동작시킨 경우 그 앞단에 로드밸런서를 배치하여 특정 파드를 클러스터 외부로 공개 할 수 있다.
AWS EKS는 쿠버네티스를 제어하는 컨트롤 플레인을 제공하는 관리형 서비스이다. 쿠버네티스 도입을 검토할 때 가장 큰벽은 컨트롤 플레인의 유지 및 운영이다. 컴포넌드들이 서로 독립적이고 비동기로 동작하기 때문에 각각의 구성 요소를 정상적으로 동작시키기 위한 설정이나 유지 운영 장애가 발생했을 때 복구가 간단하지 않다.
쿠버네티스 클러스터 외부에서 접속 할 때는 서비스를 사용해 엔드포인트를 생성할 필요가 있다.
kubeconfig 파일은 쿠버네티스 클라이언트인 kubectl이 이용할 설정 파일로 접속 대상 쿠버네티스 클러스터의 접속 정보(컨트롤 플레인 url, 인증 정보, 이용할 쿠버네티스의 네임스페이스 등)을 저장하고 있다.
쿠버네티스 클러스터는 컨테이너화된 애플리케이션을 실행하는 노드(워커 머신)의 집합이다.
쿠버네티스 클러스터는 크게 컨트롤 플리인(master node)와 node(worker node)로 구성된다.
kubectl은 kube apiserver와 커뮤니케이션하는 용도이다. etcd는 key-value저장소로 클러스터의 상태를 저장한다. 만약 클러스터 상태를 백업하고 복구하고 싶다면 etcd만 건드리면 된다.
kubelet은 모든 노드에 기본적으로 설치되는 컴포넌트이다. api 서버와 통신하며 노드의 리소스 상태를 보고하고 관리한다. -> ecs agent랑 비슷해보인다. container runtime과도 통신하며, 해당 노드 내에 띄워지는 컨테이너의 라이프 사이클을 관리하기도 한다.
쿠버네티스에서는 클러스터 하나를 네임스페이스라는 논리적 구획으로 구분하여 관리할 수 있다.
동작구조
레이블 - 쿠버네티스에서는 다양한 리소를 식별하기 위해 레이블을 사용한다.
쿠버네티스는 파드별로 서로 다른 ip주소를 할당하며 그 ip 주소에서 설정한 포트로 접속하는 네트워크 구조이다.
디플로이먼트를 이용하여 애플리케이션을 배포하면 scale in out 및 파드 유지를 자동으로 해준다.
네임스페이스는 컨테이너를 동작시키기 위한 리소느느 아니지만 컨테이너가 동작하는 클러스터를 논리적으로 사용하기 위한 리소스, 네임스페이스는 단순히 리소르를 배치하는 논리적인 구분 외에도, 리소스 쿼터, 네트워크 정책 구조가 있다.
설정 변경이 완료되더라도 레플리카셋이 남아있다면 이전 설정으로 롤백할 수 있다.
서비스
- 쿠버네티스에서는 서비스 리소를 이용하여 파드 여러개를 묶어 하나의 dns 이름으로 접속 할 수 있다.
- pod의 논리적 집합과 이에 액세스 하는 정책을 정의
- 서비스가 대상으로 하는 pod 집합은 일반적으로 selector(레이블 선택기)에 의해 결정 됩니다.
- 각 pod에는 고유한 ip 주소가 있지만 해당 ip는 서비스 없이 클러스터 외부에 노출되지 않습니다.
- 레이블은 생성 시 또는 나중에 pod에 부착할수 있습니다.
인그레스방식 쿠버네틴스 클러스터로 접근하는 입구를 만들기 위한 리소스, 인그레스 컨트롤러를 같이 사용하면 애플리케이션 여러 개를 클러스터 외부에 공개할 수 있다. eks에서는 인그레스 컨트롤러로 aws alb 인그레스 컨트롤러가 제공된다.
readiness probe : 가 실패하면 pod가 비정상 상태로 판단되어 ready 상태가 되지 않으며 서비스에서 트래픽을 보내지 않는다.
liveness probe : pod의 상태 모니터링이라고 한다. 실행 중인 파드가 정상적으로 동작하지 않으면 pod는 재시작을 시도한다. intial delay를 주지 않으면 health check 무한히 fail되어 무한루프에 빠질 수 있다.
terminating 상태일 때는 특정 앞부분동안은 서비스에서 요청을 수신하기 때문에 preStop 처리로 일정 시간 파드 종료를 대기시키는 방법을 사용할 수 있다. 그렇지 않게 된 경우 요청이 유실될 수 있다.
도커 컨테이너는 일단 동작하면 부하에 따라 호스트의 cpu나 메모리를 사용할 수있는 만큼 사용한다. 리소스 확보 경쟁이 일어난다면 안심하고 컨테이너 여러 개를 배칠 할 수 없다. 쿠버네티스에서는 파드가 사용할 cpu/memory 양을 설정하고 필요 이상으로 호스트 쪽에 부하를 주지 않도록 하는 구조가 있다.
파드 배치는 requests값을 기준으로 결정되므로 실제 부하가 많은 호스트라도 request를 받을 수 있는 여유가 있다면 새로운 파드가 배치된다. 이것이 오버커밋이라는 상태다. 이 상태가 발생하면 쿠버네티스는 일정 조건으로 파드 동작을 정지시킨다. 때문에 requests와 리밋의 차이로 일어 날 수 있는 현상을 이해하는 것이 중요하다.
cluster autoscaler는 node(host) scale 관리
- 파드를 스케일할 때 리소스가 부족해서 scale out되는 것 보다는 어떤 임계값을 보고 미리 scale하는 것을 추천한다. container는 빠르게 작동되지만 node가 뜨는것을 기다리는 것은 별로다.
HPA는 파드 스케일 관리
PodDisruptionBudget
- max un available을 통해 먼저 migration중인 pod가 정상상태가 되어야 다음 파드들이 node 마이그레이션을 진행할 수 있다.
'Tech' 카테고리의 다른 글
| [k8s] Strategy for Gitops (0) | 2024.04.27 |
|---|---|
| [K8S] AWS EKS IRSA 동작 (0) | 2024.04.23 |
| Track g4dn inference server OOM (0) | 2023.01.08 |
| Monorepo vs Multirepo (1) | 2022.10.05 |
| Object[5] (0) | 2022.04.20 |

